Models
As stated previously, we researched and experimented with various two class algorithms and data processing steps such as feature hashing and text preprocessing. After extensive testing and evaluation, we chose a model using the Decision Jungle algorithm with an SQL transformation to split the reviews into binary classes, and the text preprocessing, Extracting Key Phrases From Text, Latent Dirichlet Allocation and SMOTE modules from Azure.
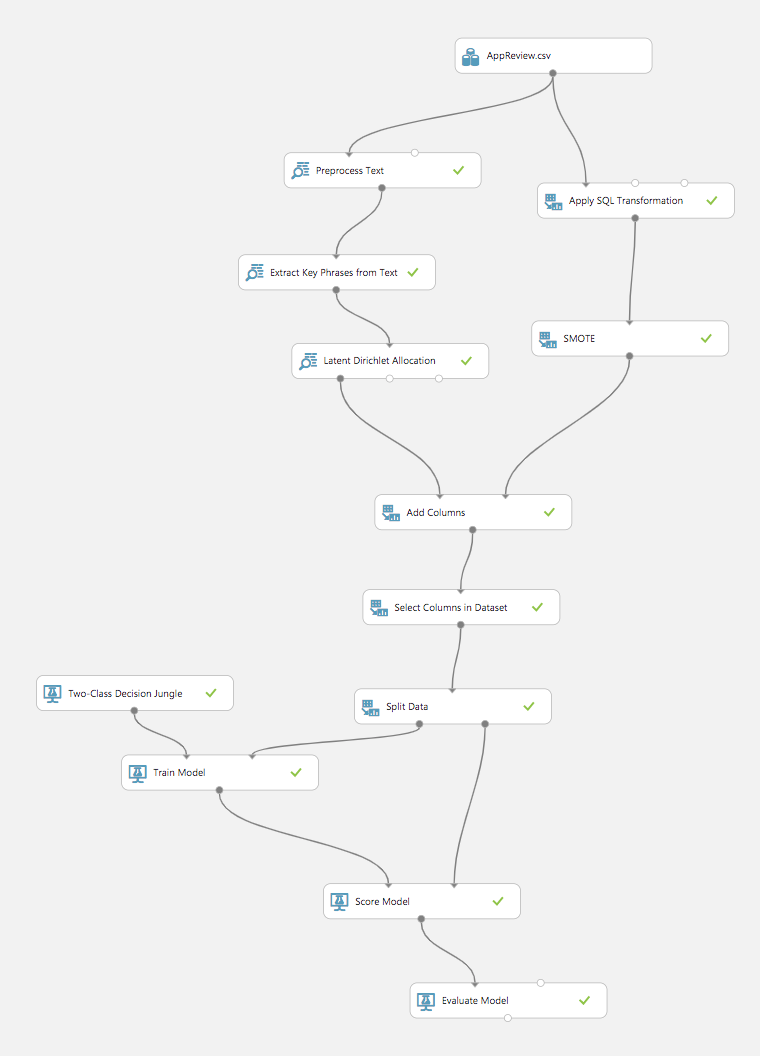 Our final model metrics:
Our final model metrics:
- At a .5 threshold, the model achieved accuracy of .926
- Precision and AUC of 1.00
- Recall of .863
- F1 of .926
- Guessed 37254 True Positive, 0 False Positive, 5932 False Negative and 37156 True Negative